Update: 18/04/2023
A znalazłem jakoś niechcący tytułowy algorytm, który w praktyce jest wykorzystywany w jakichś zaawansowanych zabawkach typu rozpoznawanie twarzy, sieci neuronowe, machine learning, GPT Czaty itp – oczywiście wuja rozumiem z takich zabawek NASA, ale algorytm jest fajny, bo potrafi w sparametryzowany sposób przerabiać więcej wymiarów na mniej zarazem grupując wg. podobieństwa parametrów.
W ramach leksykalnej poprawności: t-SNE = t-Distributed Stochastic Neighbor Embedding = stochastyczna metoda porządkowania sąsiadów w oparciu o rozkład t.
Jak ma się to do browarów PL? Ano browar na UT ma zasadniczo 3 parametry (nie całkiem niezależne, acz w teorii i owszem), a mianowicie średnią ocenę, liczbę czekinów i liczbę piw. Na niezbyt czytelnym, trójwymiarowym wykresie wygląda to tak:
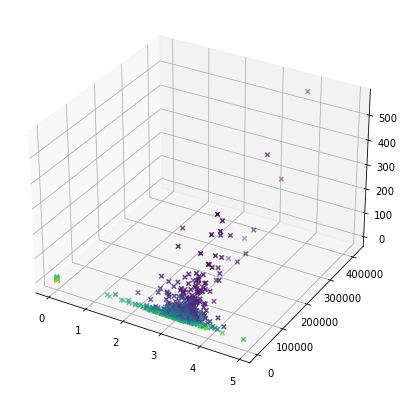
No to teraz dla różnorakich kombinacji dwóch parametrów po potraktowaniu tym T-SNE, a parametry to:
- P = Perplexity = Zmieszanie (PL tłumaczenie za IBM, acz i tak wszyscy używają tego w lengłidżu) – zasadniczo z tego co niekumam to miara jak daleko algorytm sięgnie w ramach poszukiwania sąsiadów
- LR = Learning Rate = Współczynnik Uczenia – czyli (jeśli ktoś zagugla za tymi algorytmami) odpowiada za rozmiar kroku aktualizacji gradientu
No to pyk, tak wyglądają browary PL dla różnych kombinacji wpółczynników. Jeno poglądowo, bez konkretów, bo wiadomo, że w praktycznym wykorzystaniu i zaspokojeniu własnej ciekawości raczej dobierze się jedną kombinację (ewentualnie manipulując kilkoma pozostałymi współczynnikami). Osie są niemianowane, umowne, liczy się odległość między punktami.
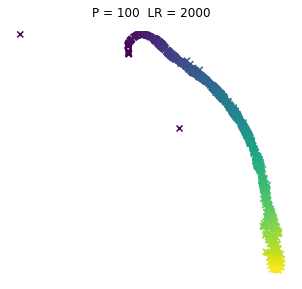
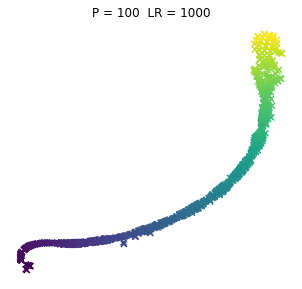
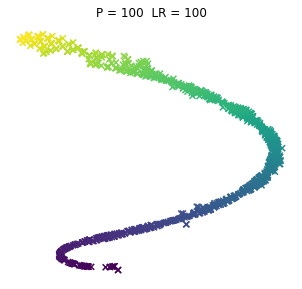


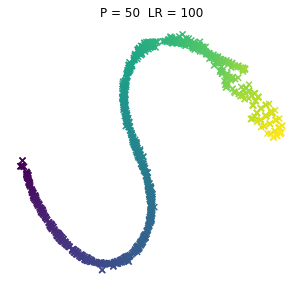
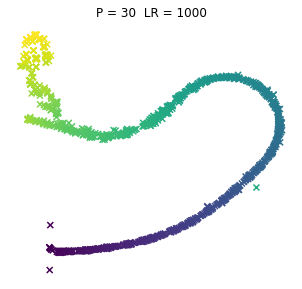
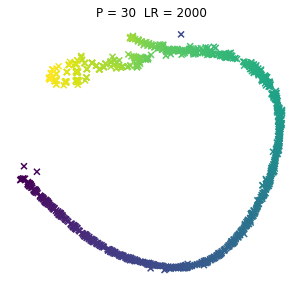
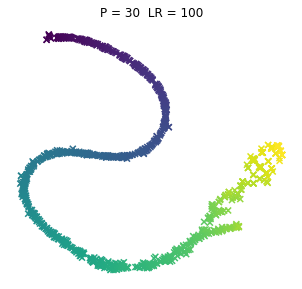

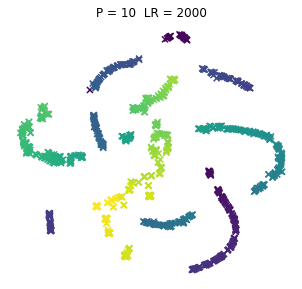
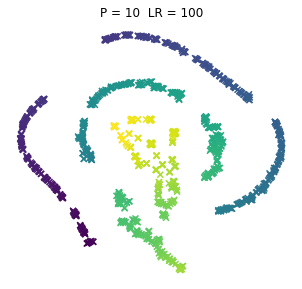
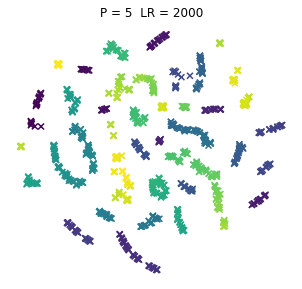


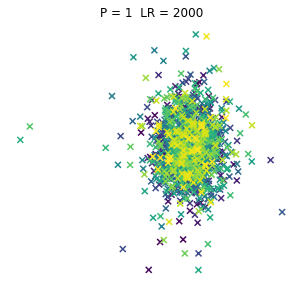
ładne, nie? 😉 Do zastosowań praktycznych jak widać dla PL browarów warto myśleć o użyciu P w okolicach 10.